突然ですがみなさん、いま東京大学でどれくらいの数の授業が開かれているか知っていますか?
全部で1000くらい?いえいえ、桁が違います。
なんと、東京大学には、約12000もの授業が開かれているんです!(2018年時点)
もし、せっかく東大に入ったからにはできるだけたくさんの授業をとりたいと意気込んで、各学期30の授業を詰め込んだとしても(大分無茶ですが)、4年間で全体の100分の1程度にしかならないわけです。
大学で研究したことのある人ならば、研究の蓄積、知識の海の膨大さに、呆然としたことが、きっとあるのではないでしょうか。

こんなにたくさん授業があると、どれが自分にとってより価値のある授業なのかわからなくなってしまいます。
できることなら、自分が学びたいことを知るためにはどの授業を受ければ良いのか、ガイドのように示してほしくはないですか?みなさん、示してほしいですよね?
実はなんと、東大の授業間の関係性が可視化されたデータベースが、すでにあるんです!
それがこのサイト→https://catalog.he.u-tokyo.ac.jp/search/
上部の検索窓に、好きなキーワードを入力してみてください。学部をまたいだたくさんの授業が、グループでまとまったり、線でつながったりした状態で表示されるはずです。
ここで活用されているのは、いまさまざまな分野で大活躍中の人工知能です。
そこで今回は、人工知能と自然言語処理を利用して、人文知を構造化する方法を紹介します。
講義動画を視聴して、データベースをうまく活用した、学問への新たなアプローチ方法について、いっしょに考えてみませんか?
人文ジャーナル『思想』を構造化する
講義動画で講師を務めているのは、人工知能による教育の体系化について研究されている美馬秀樹先生です。まさにこの美馬先生こそが、先ほど紹介した、東大学内のシラバスを構造化したご本人でもあります。

(美馬先生は、過去にこの講義動画を配信しているUTokyoOCWの運営を担当されていたこともあります。まさにOCWも、学問の知識・情報の重要な保存方法です。
OCWの授業動画を構造化したデータベースも、美馬先生によってすでに作られています。OCWのデータベースはこちら→https://ocw.u-tokyo.ac.jp/search/)
講義では、美馬先生が担当された岩波書店が発行する人文系論文のジャーナル、『思想』を構造化するプロジェクトの概要が紹介されます。
『思想』は、1921年に創刊されて以来、講義時点の2018年で約900号まで刊行されていている雑誌で、その総ページ数は16万ページにも及びます。


これが人工知能によって構造化されれば、20世紀の日本の哲学・思想の流れを大きく捉えることができるようになるはずです。
さらに、ここで文献のデジタル化に関する方法論を確立することで、人文知の構造化のモデルケースを打ち立てることもできます。
しかし、古くから刊行されている『思想』のアーカイブには、いくつかの困難がありました。
『思想』アーカイブの障壁
まず、『思想』には、デジタルのデータがありませんでした。美馬先生いわく、デジタルのテキストデータだけでなく、画像データすらなかったそうです。
そこで、カメラで紙面をスキャンして、取り込んだ画像データからテキストデータを抽出するというやり方が取られます。(手動で入力するという方法ももちろんありますが、それには数億円!の費用がかかってしまうそうです。モデルケースとして打ち立てるには非現実的だといえます)
ここでデジタルテキスト化(OCR:Optical Character Recognion)が行われることになりますが、そこにもまた、障壁がありました。

『思想』の古い文献は、印刷の精度や、紙の状態が悪く、高い精度で文字を認識することができないのです。
OCRでは、文字を要素に分解して、その組み合わせを認識することでどの文字であるかを特定していますが、その文字自体の状態が悪いと、別の文字として認識されてしまう恐れが出てきます。
また、異体字や旧字体が使われていたり、フォントが特殊であったり、ルビや強調部分があったり、レイアウトが変則的であったり、テキストを抽出するうえで厄介な要素が、さまざまにありました。
このような状況であると、ほとんど元の文とは別物になってしまう可能性があります。
実際に文字の認識精度を年代別に確認してみると、古い年代になるほど精度が下がっていることがわかります。
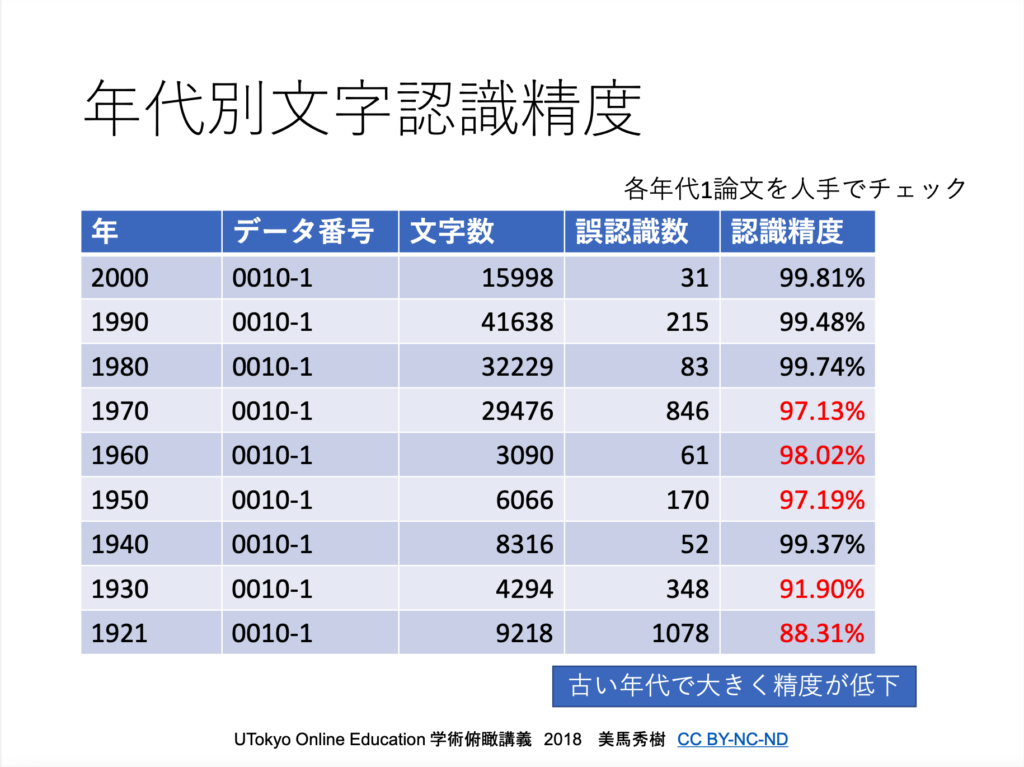
そこで美馬先生たちは、人工知能を用いて読み取りの仕方を学ばせて、文字認識精度の向上に取り組むことになりました。
たとえば、文脈を踏まえて、読み取った文字をよりもっともらしい文字におきかえるというようなことをしています。
デジタルテキストが氾濫する現代を生きているとつい見過ごしてしまいますが、知識の構造化を進めるその前に、知識をデジタル化することそれ自体に、ひとつの大きな障壁(コスト)があるということを、忘れないようにしなければいけないと思います。
人工知能による人文知の構造化
デジタルテキストが揃ったら、それを構造化する作業に移ります。
授業で紹介されるのは、美馬先生自身が作成した「MIMAサーチ」です。
記事冒頭で紹介した東大の授業のデータベースも、「MIMAサーチ」のひとつです。
このMIMAサーチを使って、一体何ができるのでしょうか?
MIMAサーチの特徴は、それぞれの論文(授業)間のつながりがわかるということです。
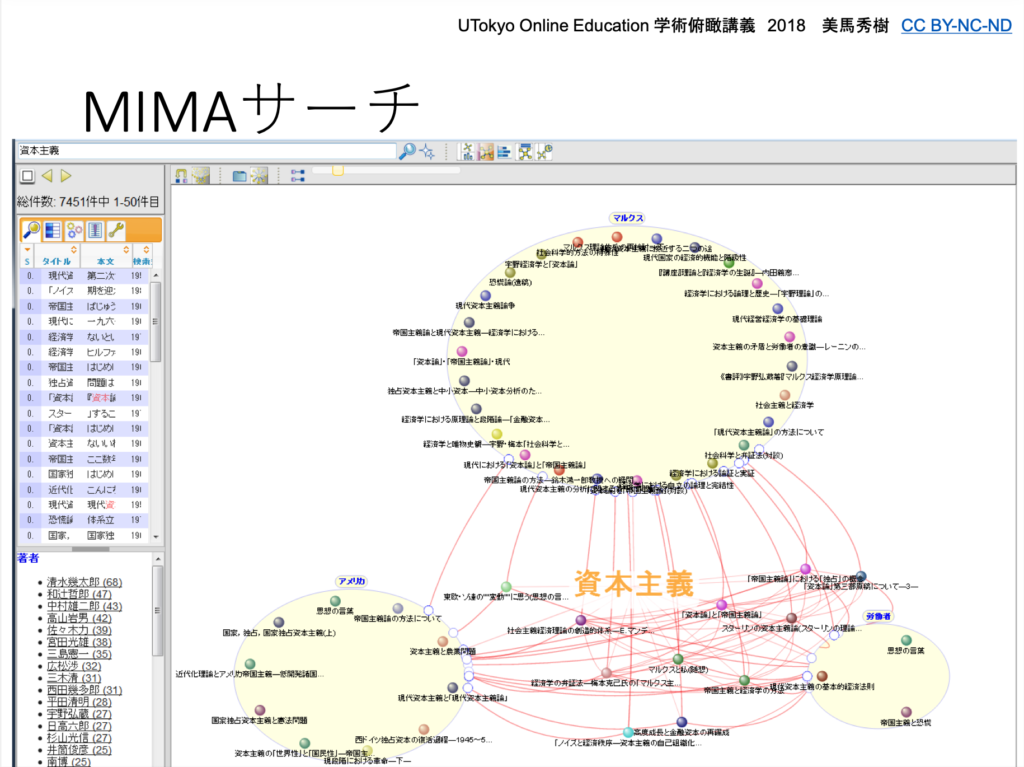
人工知能がキーワードを拾い上げてグループをつくり、またそのグループをまたいだ関係性も、線のつながりで示されます。これにより、論文の位置付けが可視化され、より自分が求める論文にアクセスしやすくなります。
そのほか、MIMAサーチ以外にも、人工知能はデジタルテキストのさまざまな活用に役立てられます。
たとえば、係り受け関係検索。人工知能によって、特定の著者や論文のなかで、どのような係り受けが頻出しているかがわかります。
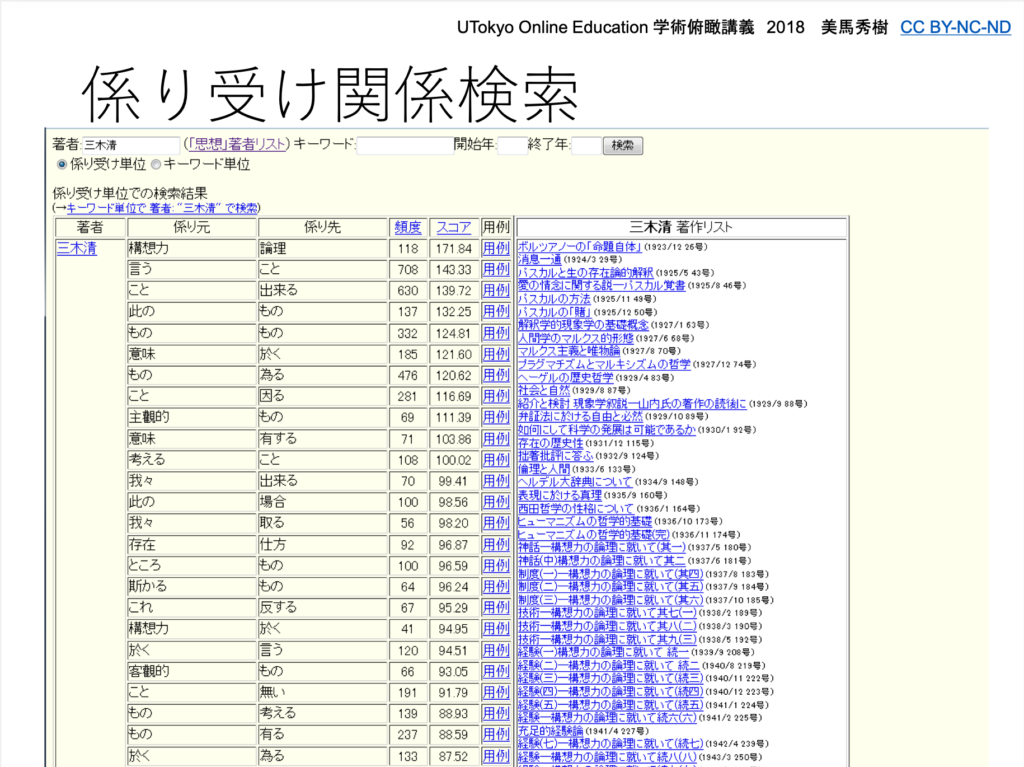
この検索を使えば、ある著者を理解するためのキーワードをつかむことができるでしょう。
次に、言及関係検索。誰が誰について言及しているかというのは、人文学における重要な要素ですが、人工知能を使えば、これもまた可視化することができます。
係り受け関係検索によって、ある著者のキーワードがわかるとするならば、言及関係検索では、ある時点における分野の「キーマン」をつかむことができるといえそうです。

これからの知の構造化のために
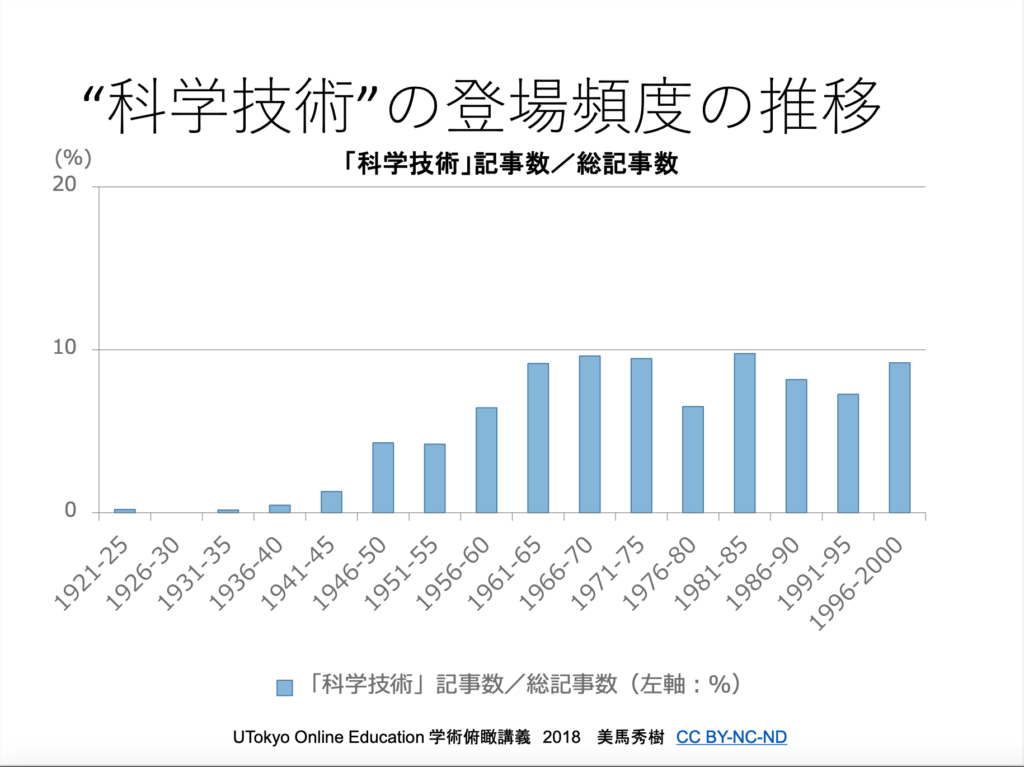
そのほかにも、人文知の構造化のために人工知能が果たせる役割は、幅広くあります。たとえば「科学技術」というような用語がいつごろから使われ出したのか、概念の変遷をたどるというのもそのひとつでしょう。
知の構造化を進めるためには、人工知能の研究者だけでなく、この場合は人文学者など、諸学問の専門家が知恵を出し合っていく必要があります。つまり、ある種の文理融合が必須です。
美馬先生は、知の構造化が進めば、言語の壁を越え、海外の研究へのアクセスも行いやすくなるといいます。もしそうなれば、学問が新たな発展を見せることになるでしょう。
知の構造化は、間違いなくこれから進歩していく分野です。みなさんも、まずはこれらのデータベースを活用し、より良い活用法や今後の可能性について、考えてみてください。
今回紹介した講義:デジタル・ヒューマニティーズ ― 変貌する学問の地平 ― (学術俯瞰講義) 第6回 人工知能と自然言語処理技術を利用した人文知の構造化 美馬 秀樹先生
<文/竹村直也(東京大学オンライン教育支援サポーター)>
