2005年度開講
言語情報科学
日本語、英語などの自然言語の計算機処理に関する基礎的項目の概観と応用の紹介を行う。特にこの授業ではテキストとして書かれた言語の処理を扱う。
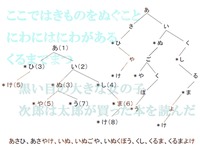
前半では言語学に立脚する自然言語処理について述べる。すなわち、意味を持つ最も小さな言語単位である形態素の解析から初めて順次より大きな言語単位の処理に進む。すなわち、句、節、文、そして文の連続である談話である。
中盤は1990年代以降盛んになった統計学に基礎を置く、いわゆる統計的自然言語処理の基礎について説明する。
後半は統計的自然言語処理の重要な応用、すなわち情報抽出、要約、機械翻訳、情報検索について紹介する。
最終回は以上で説明してきたことを総括して、その歴史的意義付けと未来の方向性を議論する。
講義一覧
第11回
テキストからのデータマインニング
|
中川 裕志
おすすめの講義






